
If you are looking for an easy-to-use and highly expandable mail relay service, SendGrid represents the most developer-friendly solution out in the market today. What’s even better is that it’s available on Azure, making it the ideal choice if you are developing an existing solution on the Azure stack. The best thing I like about the service is the extensive documentation covering every aspect of its Web API, structured to provide a clear explanation of endpoint methods, required properties, and example outputs - exactly the right way that all technical documentation should be laid out.
I recently had a requirement to integrate with the SendGrid API to extrapolate email statistic information into a SQL database. My initial thoughts were that I would need to resort to a bespoke C# solution to achieve these requirements. However, keenly remembering my commitment this year to find opportunities to utilise the service more, I decided to investigate whether Microsoft Flow could streamline this process. Suffice to say, I was pleasantly surprised and what I wanted to do as part of this week’s blog post was demonstrate how I was able to take advantage of Microsoft Flow to deliver my requirements. In the process, I hope to get you thinking about how you approach integration requirements in the future, challenging some of the pre-conceptions around this.
Before we get into creating the Flow itself…
…you will need to create a table within your SQL database to store the requisite data. This script should do the trick:
CREATE TABLE [dbo].[SendGridStatistic]
(
[SendGridStatisticUID] [uniqueidentifier] NULL DEFAULT NEWID(),
[Date] DATE NOT NULL,
[CategoryName] VARCHAR(50) NULL,
[Blocks] FLOAT NOT NULL,
[BounceDrops] FLOAT NOT NULL,
[Bounces] FLOAT NOT NULL,
[Clicks] FLOAT NOT NULL,
[Deferred] FLOAT NOT NULL,
[Delivered] FLOAT NOT NULL,
[InvalidEmail] FLOAT NOT NULL,
[Opens] FLOAT NOT NULL,
[Processed] FLOAT NOT NULL,
[SpamReportDrops] FLOAT NOT NULL,
[SpamReports] FLOAT NOT NULL,
[UniqueClicks] FLOAT NOT NULL,
[UniqueOpens] FLOAT NOT NULL,
[UnsubscribeDrops] FLOAT NOT NULL,
[Unsubscribes] FLOAT NOT NULL
)
A few things to point out with the above:
- The CategoryName field is only required if you are wishing to return statistic information grouped by category from the API. The example that follows primarily covers this scenario, but I will also demonstrate how to return consolidated statistic information as well if you wanted to exclude this column.
- Microsoft Flow will only be able to map the individual statistic count values to FLOAT fields. If you attempt to use an INT, BIGINT etc. data type, then the option to map these fields will not appear. Kind of annoying, given that FLOATs are effectively “dirty”, imprecise numbers, but given the fact we are not working with decimal numbers, this shouldn’t cause any real problems.
- The SendGridStatisticUID is technically optional and could be replaced by an INT/IDENTITY seed instead or removed entirely. Remember though that it is always good practice to have a unique column value for each table, to aid in individual record operations.
With everything ready, we can now “Flow” quite nicely into building things out. The screenshot below demonstrates how the completed Flow should look from start to finish. The sections that follow will discuss what is required for each constituent element
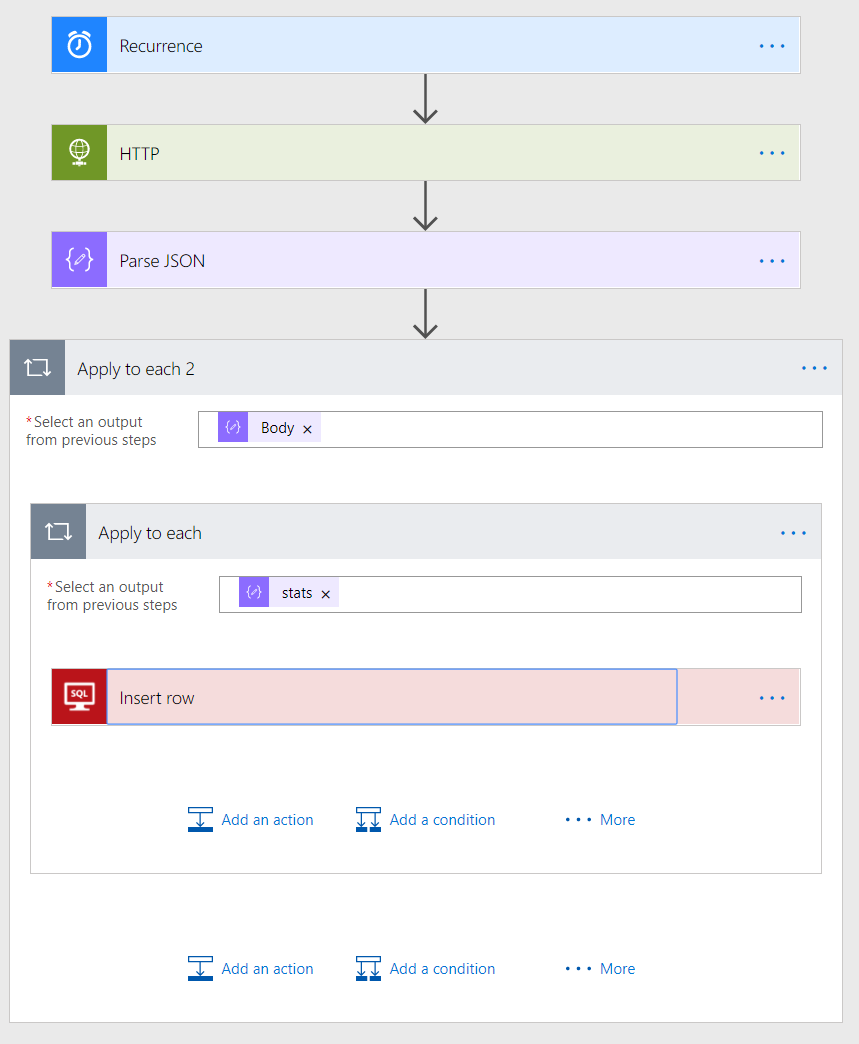
Recurrence
The major boon when working with Flow is the diverse options you have for triggering them - either based on certain conditions within an application or just simply based off a recurring schedule. For this example, as we will be extracting statistic information for an entire 24 period, you should ensure that the Flow executes at least once daily. The precise timing of this is up to you, but for this example, I have suggested 2 AM local time each day. The configured recurrence settings should resemble the below if done correctly:
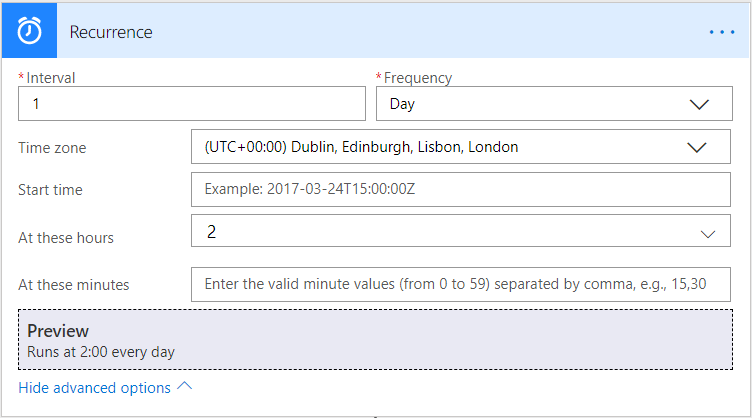
You should be aware that when your Flow is first activated, it will execute straightaway, regardless of what settings you have configured above.
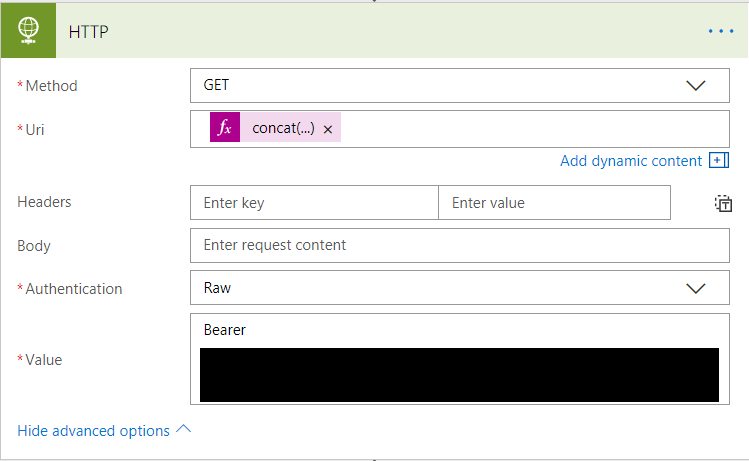
HTTP
As the SendGrid Web API is an HTTP endpoint, we can utilise the built-in HTTP connector to retrieve the information we need. This is done via a GET operation, with authentication achieved via a Raw header value containing the API key generated earlier. The tricky bit comes when building the URI and how we want the Flow to retrieve our information - namely, all statistic information covering the previous day. There is also the (optional) requirement of ensuring that statistic information is grouped by category when retrieved. Fortunately, we can get around this problem by using a bit of Expression trickery to build a dynamic URI value each time the Flow is executed. The expression code to use will depend on whether or not you require category grouping. I have provided both examples below, so simply choose the one that meets your specific requirement:
Retrieve Consolidated Statistics
concat('https://api.sendgrid.com/v3/stats?start_date=', string(getPastTime(1, 'day', 'yyyy-MM-dd')), '&end_date=', string(getPastTime(1, 'day', 'yyyy-MM-dd')))
Retrieve Statistics Grouped By Category
concat('https://api.sendgrid.com/v3/categories/stats?start_date=', string(getPastTime(1, 'day', 'yyyy-MM-dd')), '&end_date=', string(getPastTime(1, 'day', 'yyyy-MM-dd')), '&categories=cat1&categories=cat2')
Note: For this example, statistic information would be returned only for the categories that equal cat1 & cat2. These should be updated to suit your requirements, and you can add on additional categories by extending the URI value like so: &categories=cat3&categories=cat4 etc.
Your completed HTTP component should resemble the below if done correctly. Note in particular the requirement to have Bearer and a space before specifying your API key:
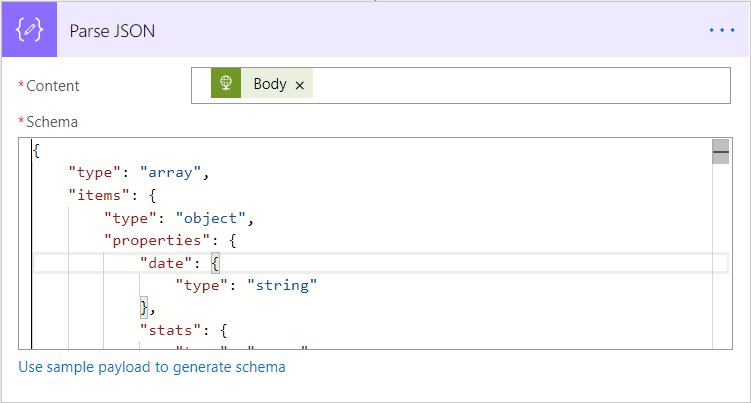
Parse JSON
A successful 200 response to the Web API endpoint will return a JSON object, listing all statistic information grouped by date (and category, if used). I always struggle when it comes to working with JSON - a symptom of working too long with relational databases I think - and they are always challenging for me when attempting to serialize result sets. Once again, Flow comes to the rescue by providing a Parse JSON component. This was introduced with what appears to be little fanfare last year, but really proves its capabilities in this scenario. The only bit you will need to worry about is providing a sample schema so that the service can properly interpret your data. The Use sample payload to generate schema option is the surest way of achieving this, and you can use the example payloads provided on the SendGrid website to facilitate this:
Retrieve Consolidated Statistics: https://sendgrid.com/docs/API_Reference/Web_API_v3/Stats/global.html
Retrieve Statistics Grouped By Category: https://sendgrid.com/docs/API_Reference/Web_API_v3/Stats/categories.html
An example screenshot is provided below in case you get stuck with this:
Getting the records into the database
Here’s where things get confusing…at least for me when I was building out this flow for the first time. When you attempt to add in an Insert row step to the flow and specify your input from the Parse JSON step, Microsoft Flow will automatically add two Apply to each step to properly handle the input. I can understand why this is the case, given that we are working with a nested JSON response, but it does provide an ample opportunity to revisit an internet meme of old…

With the above ready and primed, you can begin to populate your Insert row step. Your first step here will more than likely be to configure your database connection settings using the + Add New Connection option:
The nicest thing about this is that you can utilise the on-premise gateway service to connect to a non-cloud database if required. Usual rules apply, regardless of where your database is located - use a minimum privileged account, configure any required IP whitelisting etc.
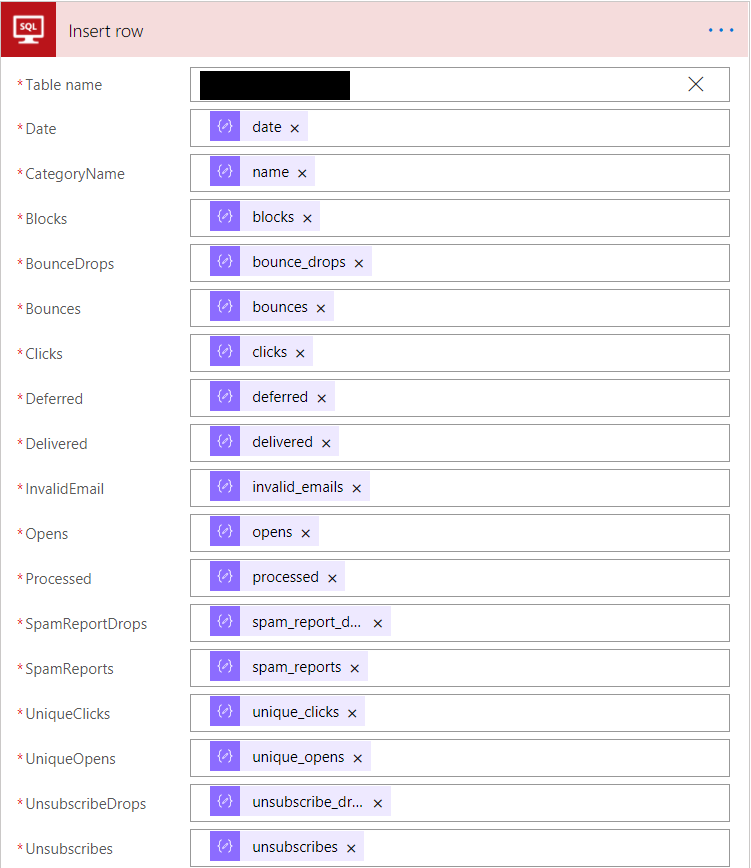
With your connection configured, all that’s left is to provide the name of your table and then perform a field mapping exercise from the JSON response. If you are utilising the SendGridStatisticUID field, then this should be left blank to ensure that the default constraint kicks in correctly on the database side:
The Proof is in the Pudding: Testing your Flow
All that’s left now is to test your Flow. As highlighted earlier in the post, your Flow will automatically execute after being enabled, meaning that you will be in a position to determine very quickly if things are working or not. Assuming everything executes OK, you can verify that your database table resembles the below example:

This example output utilises the CategoryName value, which will result in multiple data rows for each date, depending on the number of categories you are working with. This is why the SendGridStatisticUID is so handy for this scenario 🙂
Conclusions or Wot I Think
When it came to delivering the requirements as set out in this posts introduction, I cannot overemphasise how much Microsoft Flow saved my bacon. My initial scoping exercise around this strongly led me towards having to develop a fully bespoke solution in code, with additional work than required to deploy this out to a dedicated environment for continuous execution. This would have surely led to:
- Increased deployment time
- Additional cost for the provisioning of a dedicated execution environment
- Wasted time/effort due to bug-fixing or unforeseen errors
- Long-term problems resulting from maintaining a custom code base and ensuring that other colleagues within the business could properly interpret the code correctly.
Instead, I was able to design, build and fully test the above solution in less than 2 hours, utilising a platform that has a wide array of documentation and online support and which, for our particular scenario, did not result in any additional cost. And this, I feel, best summarises the value that Microsoft Flow can bring to the table. It overturns many of the assumptions that you generally have to make when implementing complex integration requirements, allowing you to instead focus on delivering an effective solution quickly and neatly. And, for those who need a bit more punch due to very highly specific business requirements, then Azure Logic Apps act as the perfect meeting ground for both sides of the spectrum. The next time you find yourself staring down the abyss of a seemingly impossible integration requirement, take a look at what Microsoft Flow can offer. You just might surprise yourself.