
When you first begin working with the Dynamics CRM SDK, there is a lot of specific terminology, concepts and methods that need to be grasped firmly. The importance of this is twofold: it enables you to judge the best approach when developing your bespoke solution that fits in within CRM and allows you to gain a very good understanding of the underlying CRM platform. The terms “early-bound” and “late-bound” are, arguably, the most important of these terms/concepts to fully understand, so it is useful to first explain what each of these refer to and the benefits & drawbacks of each, before we get into this weeks blog post properly:
Early Bound
Early bound refers to when you are using a generated class file to access all of the customization data for your CRM within your code. The SDK Bin folder contains an executable file called CrmSvcUtil, which can be used to generate this file. There is a great MSDN article that goes through the steps involved as part of this; once you’ve got the file, simply add it into your Visual Studio project and Intellisense will automatically detect your entity, relationship etc. names! Suffice to say, going down the early bound route can significantly ease your development work, as your strongly-typed class file will contain everything you would require regarding your CRM entities. As such, you will be able to ensure that your code is accessing the correct attributes, relationships and other objects within CRM at all times.
Given that it makes a developers jobs ten times easier, why wouldn’t you want to use Early Bound in your code all the time? Your strongly-typed class file is essentially a snapshot of your current CRM instance, at the date and time when you ran the CrmSvcUtil. As soon as someone makes a change within CRM, your class file may no longer be correct and you may encounter major problems when executing your code against your target CRM environment. This problem can also be compounded if you are developing an ISV solution that is executed against a varied number of environments, where there could be entities/attributes present that your code has no reasonable way to anticipate; in this case, it becomes absolutely essential for you to consider using late-binding instead within your code.
Late Bound
Late binding is the exact opposite of early binding. To access your CRM entities via the late-bound route, you use the Microsoft.Xrm.Sdk.Entity class to declare the new or existing entity that you wish to work with within your code. Typically, you will need to have your CRM Solution open in front of you as part of using late-binding, so that you can reference the logical names of your entities & attributes. You are therefore not “restricted” in the same way that you are with early-binding - you can declare any possible logical name for your CRM objects that you want, which, as mentioned already, is essential if you are blind to the CRM instance(s) in question. There is also a performance benefit to using the late-bound Entiy class, depending on the number of records your code is working with. According to the following Microsoft best practice article:
In addition, if your custom code works with thousands of entity records, use of the Entity class results in slightly better performance than the early-bound entity types.
One of the major drawbacks of using late binding is the increased chance of errors in your code, as you will need to ensure that your logical names are typed correctly; any such mistakes, as we will demonstrate further below, may cause your code to fall over straight away and lead to hours of frustrating debugging in order to resolve.
Now, to the heart of the matter…
I recently had a conversation with a developer colleague, who gave me some advice in relation to some plugin code I had written. Within my code, I had attempted to access the value of a Single Line of Text Entity attribute, using late-bound classes, in the following manner:
string myAttribute = myEntity["myattribute"].ToString();
They recommended instead that I look at using the GetAttributeValue method instead, which in this case, would be expressed in the following manner
string myAttribute = myEntity.GetAttributeValue<string>("myattribute");
My colleague elaborated on a few reasons why this approach is preferential (which I will discuss at the end of this post), but I was interested in dissecting this further myself, to see how it works in practice. In my test CRM instance, I created a plugin for the Contact entity, that would fire on the Post-Operation event of the Update Message, for the First Name field. The plugin very simply accesses the value of this field using the two different approaches, which can be done like so:
//First, initialize your Contact entity
Entity contact = (Entity)context.InputParameters["Target"];
//Now we can access our attributes - the first way is like this...
string contactField1 = contact["firstname"].ToString();
//The second way...
string contactField2 = contact.GetAttributeValue<string>("firstname");
When we play back the plugin execution in Visual Studio, we can see that this returns our expected values. In this particular example, we have attempted to rename our “Homer Simpson” Contact record to “Bart Simpson”:


So, at this stage, there does not appear to be a clear benefit of using one snippet over the other. But what happens if we attempt to access an attribute that does not exist? We can test this by adding the following lines of code to our plugin:
//Next, we test what happens if there is a typo - first, we try GetAttributeValue
string contactField3 = contact.GetAttributeValue<string>("thiswillerror");
//Then, the alternate way
string contactField4 = contact["thiswillerror"].ToString();
When we use our GetAttributeValue approach, our contactField3 returns a null value… :

Whereas our contactField4 instantly causes an error, which would also be returned to the user within CRM…
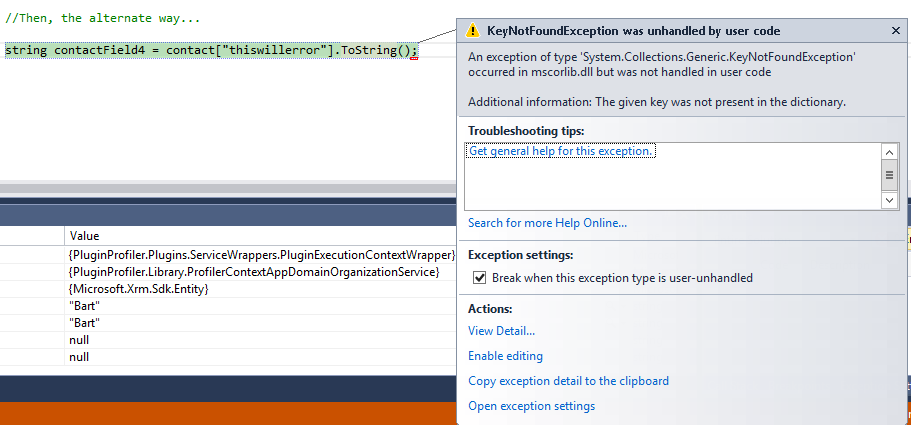
Where possible, we always want to try and prevent an Exception from being passed back to CRM and build in the appropriate error handling within our code, and this was one of the benefits that my colleague highlighted in this approach. So, for example, you can build in an if…else statement as part of the above example that checks whether the GetAttributeValue is Null and then perform the appropriate action, depending on the result. Having spent time working with the method more closely, I can also now see a clear benefit in relation to code readability - it is definitely more obvious what GetAttributeValue is doing within a code example, compared with the alternative approach, as well as making it obvious what the data type of the attribute is within CRM. Keep in mind however that you still need to ensure that you are using your correct Data Types, both when creating your C# variables and referencing your CRM attributes - for example, you cannot return the contactid field as a string, as this will generate an InvalidCastException.
To finish off, I would invite you to look through this excellent article from Guido Preite, that takes a deep-dive look at the GetAttributeValue method in a variety of different scenarios. Definitely one to save to your bookmarks 🙂