
During my time working in IT, I’ve seen and dealt with my fair share of bizarre issues - ones which I can easily term as “WTF” in both their cause and potential resolution. What’s worse is when they occur using a system that, ostensibly, you think you have a pretty good handle over. Clearly, despite often having years or decades or familiarity with something, you can never honestly claim to be a total expert in something - a state of affairs that you can derive both comfort and frustration out of in equal measure. Take Microsoft SQL Server as a prime example for me. As my “first love” when it comes to working with Microsoft technologies, I feel I have a good grasp of the subject area and, in particular, on how the concept of computed columns work. Columns of this type have their values generated on the fly, often deriving from a formula. So, for example, take the amount specified within Col1 and multiply it against Col2 in the same row. In their default state, computed column values are not stored within a table, unless you use the PERSISTED option when creating them. Regardless of how you use them, they provide database developers with a smooth and powerful way to generate semi-dynamic column outputs.
Recently, I was working with a SQL Database project in Visual Studio, creating a table with a PERSISTED computed column. The definition for this table looked a little something like this:
CREATE TABLE dbo.MyTable
(
MyPKField NUMERIC(12, 0) PRIMARY KEY,
MyIntegerField INT NOT NULL,
MyPersistedColumn AS CAST(MyIntegerField AS NVARCHAR(20)) PERSISTED,
);
To explain the “why” behind using the Persisted Column in the first place, this was so that the application linked to the database could more easily retrieve values when using a WHERE query targeting this field, via a Nonclustered Index I had setup. Attempting to perform any data type conversions as part of your queries can often force the generated query plan not to utilise any indexes you have specified. Therefore, you should pay attention to any unnecessary type conversions within your query and, as per this example, provide a column of the correct type in the source table.
Now, to go back to the theme of bizarre issues…in this case, whenever I deployed out the database project as a DACPAC deployment into SQL Server, the table was being dropped and recreated every single time. Given this table contained many millions of rows and had several different views, indexes etc. linked to it, this meant that each deployment also then had to DROP/CREATE these objects as well. This circumstance greatly inflated the deployment time for the database - partly because the publish action also recreates tables in a fashion that prevents data loss (provided you’ve enabled the Block incremental deployment if data loss might occurred option in your publish profile). It does this by creating a new table, inserting all records from the existing table into it and then performing a DROP/rename on the new table. All of this, in conclusion, contributes to the length of the deployment. So, in theory, you could treat all this as a minor annoyance. But in practice, having to sit around while it took close to an hour to deploy out all database changes is not something I’d want to inflict on myself or anyone else 🙂
So with all this in mind, I started doing some research. Initially, I came across the following post on StackExchange, with a solution that seemed sensible - namely, explicitly define the column as NOT NULL, like so:
CREATE TABLE dbo.MyTable
(
MyPKField NUMERIC(12, 0) PRIMARY KEY,
MyIntegerField INT NOT NULL,
MyPersistedColumn AS CAST(MyIntegerField AS NVARCHAR(20)) PERSISTED NOT NULL,
);
Making this modification didn’t work though. So some more extensive investigation and, as it turns out, comparison action would be required to determine the root cause. Fortunately, if you are using SQL Server Data Tools (SSDT) within Visual Studio, there is a handy option available that lets us compare database schemas and produce a list of differences. As part of this, you can select an existing database, reference a database project or select a physical DACPAC file as part of your analysis. I won’t go into too much detail about this feature, as you can read up more about it on the Microsoft Docs website, but its a useful tool to consider when diagnosing problems like this. You can access it by navigating to Tools -> SQL Server -> New Schema Comparison… within Visual Studio:
Using this tool, I ran a comparison against the deployed database and the database project and discovered something interesting. Can you spot this in the (heavily redacted) screenshot below?
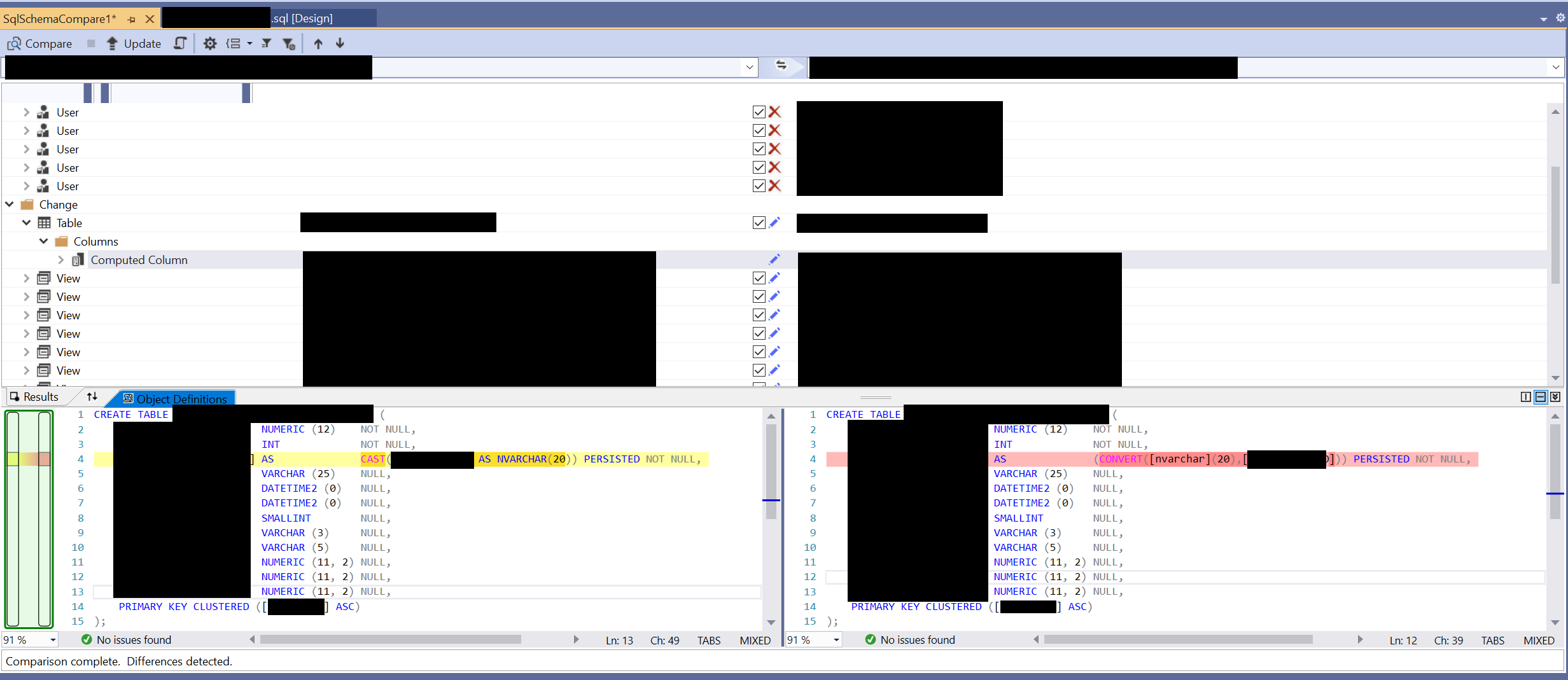
For those who didn’t spot it, take a look at line 4 within the Object Definitions. For the database project, we have defined a CAST to perform the data conversion of the MyIntegerField. Yet the database itself is using a CONVERT instead. So, from the looks of it, the DACPAC deployment is creating the column using CONVERT instead. Given that these functions are virtually identical, as attested to by Microsoft, you can perhaps understand why a DACPAC deployment may choose to use one variant over the other. But regardless of this fact, the DACPAC deployment was detecting that the schema was different and creating the appropriate statements to DROP / CREATE the table again. Very bizarre!
So how to get around this then? By simply changing the CREATE TABLE script in the database project to use CONVERT instead, like so…
CREATE TABLE dbo.MyTable
(
MyPKField NUMERIC(12, 0) PRIMARY KEY,
MyIntegerField INT NOT NULL,
MyPersistedColumn AS CONVERT(NVARCHAR(20), MyIntegerField) PERSISTED NOT NULL,
);
…the DACPAC deployment no longer detects that the destination schema has changed and stops DROPping the table each time.
As mentioned already, I would certainly class this as one of the most bizarre issues I have come across when working with SQL Server and Visual Studio. The only reason I can think of is that the DACPAC deployment prefers the use of CONVERT (which is a T-SQL specific function) over CAST because it has some enhanced options around date formatting which may be useful, depending on your scenario. Regardless, thanks to some of the valuable tools available as part of SSDT, we can diagnose issues like this and take the appropriate steps to get our database project fixed and, in the process, save us from waiting around ages while our deployments complete 🙂